运用统计方法进行数据分析时,常常要求数据满足一定的条件,如正态性、方差齐性、独立性等。数据是否满足假设,需要检验。在总体分布函数完全未知或只知分布形式,但不知其参数时,为了推断总体的某些性质,需要提出关于总体的假设。假设是否合理,也需要检验。[大谦Excel,dqexcel点com]
相关概念
假设检验中有几个概念需要掌握。
1.原假设(零假设)、备择假设
进行假设检验时,首先需要给出关于总体的某个假设。例如,假设在显著性水平下,检验样本均值 是否等于总体均值 0,即检验假设
H0: =0 H1: ≠0
则称H0为原假设(或零假设),称H1为备择假设。
2.统计量、显著性概率和显著性水平
进行假设检验时,首先需要构造一个统计量,它服从某个已知的分布。利用样本数据计算出统计量的值,根据已知分布的累加分布函数可以计算出该统计量值对应的概率,即显著性概率。显著性水平是给定的一个概率值,比如0.05或0.01等。当计算得到的显著性概率小于给定的显著性水平,就说在这个显著性水平上拒绝零假设。也可以根据显著性水平和已知分布得到统计量,用计算得到的统计量值与它比较来确定是否接受零假设。
3.拒绝域、临界点
当检验统计量取某个区域中的值时,拒绝原假设,则称该取值区域为拒绝域,称拒绝域的边界点为临界点。
4.第1类错误、第2类错误
当零假设实际上为真,却拒绝零假设时所犯的错误称为“弃真”错误,或第1类错误;当零假设实际上不为真,却接受零假设时所犯的错误称为“取伪”错误,或第2类错误。
5.双边检验、单边检验
对于上面的假设问题,如果备择假设表示不等于0,则称这种假设检验为双边检验;如果备择假设为大于0,或小于0,则称这种假设检验为单边检验。
正态分布检验
假设检验、方差分析等常常要求数据总体服从正态分布,所以,检验或分析之前需要对数据总体进行正态分布检验。本小节介绍几种常用的正态分布检验方法,包括Shapiro-Wilk检验、Anderson-Darling检验、Jarque-Bera检验、QQ图和PP图检验。
1. Shapiro-Wilk检验
Shapiro-Wilk检验常用于小样本数据的正态分布检验。Python的Scipy包提供了stats.shapiro函数实现该检验。
图4-11工作表A列为抽样调查某地20名3岁女孩身高(cm)的原始数据,要求检验样本所属的总体是否服从正态分布。零假设为服从正态分布。

图4-11 shapiro正态分布检验
C2单元格中在Python模式下在公式栏中输入下面的代码:
from scipy import stats as st
data=xl("A1:A20").values
r=st.shapiro(data)单击Ctrl+Enter键,返回一个元组对象。该元组中包括两个元素,分别为检验统计量和显著性概率p值。如图4-11所示,p值大于0.05,所以在0.05的显著性水平上接受零假设,认为数据所属的总体服从正态分布。
2. Anderson-Darling检验
大样本数据可用Anderson-Darling检验进行正态分布检验。Python的Scipy包提供了stats.anderson函数实现该检验。
图4-12工作表B列为42台微波辐射(开门时)的辐射量数据。现检验数据所属总体是否服从正态分布。零假设为服从正态分布。

图4-12 Anderson正态分布检验
D2单元格中在Python模式下在公式栏中输入下面的代码:
from scipy import stats as st
data=xl("A1:B43",headers=True)
r=st.anderson(data['辐射量'].values)单击Ctrl+Enter键,返回一个元组对象r。该元组中包括3个元素,第1个元素为检验统计量2.807209,第2个和第3个元素为NumPy数组,如图4-12所示。
D6单元格中在Python模式下在公式栏中输入下面的代码:
r[1]单击Ctrl+Enter键,返回元组r中的第2个元素,它是一个NumPy数组。显示该数组为[0.533 0.607 0.728 0.849 1.01]。该结果要结合元组r中的第3个元素来阅读。
D7单元格中在Python模式下在公式栏中输入下面的代码:
r[2]单击Ctrl+Enter键,返回元组r中的第3个元素,它是一个NumPy数组。显示该数组为[15 10 5 2.5 1]。
上面两个NumPy数组都有5个元素,第2个数组中的元素表示的是显著性水平,即0.15, 0.10, 0.05, 0.025和0.01。第1个数组中的5个元素是与这5个显著性水平对应的统计量临界值。用元组r的第1个元素即计算统计量跟这几个临界值进行比较,发现计算统计量比0.01对应的临界值1.01还要大,所以可以在0.01的显著性水平上拒绝零假设,认为数据所属总体不服从正态分布。
3. Jarque-Bera检验
Jarque-Bera检验是一种双侧拟合优度检验,适合于分布未知,参数必须进行估计的情况。Python的Scipy包提供了stats.jarque_bera函数实现该检验。
图4-13工作表A列为84个伊特拉斯坎人男子的头颅的最大宽度(mm),试检验这些数据所属的总体是否服从正态分布。零假设为服从正态分布。

图4-13 Jarque Bera正态分布检验
C2单元格中在Python模式下在公式栏中输入下面的代码:
from scipy import stats as st
data=xl("A1:A84").values
r=st.jarque_bera(data)单击Ctrl+Enter键,返回一个元组对象r。该元组中包括2个元素,第1个元素为检验统计量,第2个元素为显著性概率p值。p值大于0.05,所以在0.05的显著性水平上接受零假设,认为数据所属的总体服从正态分布。
4. QQ图和PP图
常常用QQ图和PP图进行正态分布检验。
QQ图用数据分布的分位数与所指定分布的分位数之间的关系曲线来检验数据的分布。如果两个样本来自同一分布,则图中数据点近似呈直线关系,否则为曲线关系。
PP图与QQ图类似,只是绘图时用的是数据分布的显著性概率和所指定分布的显著性概率,即实测值和理论值对应的显著性概率。
使用statsmodels.graphics.gofplots子包下面的qqplot函数和ppplot函数绘QQ图和PP图。

图4-14 用QQ图和PP图进行正态分布检验
图4-14工作表的第1列和第2列分别为前面进行Shapiro-Wilk检验和Anderson-Darling检验的数据。利用它们绘QQ图和PP图。
C2单元格中在Python模式下在公式栏中输入下面的代码:
from statsmodels.graphics.gofplots as sm
data=xl("A1:A20")[0].values
x=sm.ProbPlot(data,fit=True)
x.qqplot(line=’45’)单击Ctrl+Enter键,返回一个Image对象。合并单元格区域E2:I13,显示QQ图如图4-14所示。
C16单元格中在Python模式下在公式栏中输入下面的代码:
x.ppplot(line=’45’)单击Ctrl+Enter键,返回一个Image对象。合并单元格区域E16:I28,显示PP图。
可见,第1个数据的QQ图和PP图中,散点基本围绕45度斜线波动,说明数据所属总体服从正态分布。
使用第2列的数据绘QQ图和PP图。
J2单元格中在Python模式下在公式栏中输入下面的代码:
from statsmodels.graphics.gofplots as sm
data=xl("B1:B42")[0].values
x=sm.ProbPlot(data,fit=True)
x.qqplot(line=’45’)单击Ctrl+Enter键,返回一个Image对象。合并单元格区域K2:O13,显示QQ图如图4-14所示。
J16单元格中在Python模式下在公式栏中输入下面的代码:
x.ppplot(line=’45’)单击Ctrl+Enter键,返回一个Image对象。合并单元格区域K16:O28,显示PP图。
可见,第2个数据的QQ图和PP图中,散点呈现明显的曲线特征,说明数据所属总体不服从正态分布。
5. 数据不服从正态分布怎么处理?
数据如果不服从正态分布怎么办呢?主要有两个办法,第1是使用第5章数据预处理部分介绍的数据转换方法,将数据转换为服从正态分布再处理;第2是不转换数据,使用非参数的统计分析方法,如本章后面要介绍的非参数假设检验方法和非参数方差分析方法。
方差齐性检验
参数统计分析方法除了常常要求数据服从正态分布外,还要求数据满足方差齐性。所谓方差齐性,对于单样本要求其方差等于总体方差,对于两个及两个以上的样本,要求各样本所属总体具有相等的方差。
单个正态总体的方差齐性检验
对于单个正态总体,比较样本方差与总体方差之间的差异。构造统计量:
其中,n为样本大小,s为样本标准差,为总体的标准差。
零假设下,统计量T服从自由度为n-1的卡方分布。
图4-15工作表A列为测得的一批钢件20个样品的屈服点(单位:T/CM2),假设屈服点服从正态分布。已知总体标准差为0.2,试对该样本的数据进行方差检验。零假设为该样本的方差与总体方差之间没有显著差别。

图4-15 单个正态总体方差齐性检验
C2单元格中在Python模式下在公式栏中输入下面的代码:
from scipy import stats as st
data=xl("A1:A20").values
chi2=st.chi2(len(data)-1)
stat=(len(data)-1)*np.var(data)/0.2/0.2
2*min(chi2.cdf(stat),1-chi2.cdf(stat))单击Ctrl+Enter键,返回显著性概率p值。p值大于0.05,所以在0.05显著性水平上接受零假设,认为样本方差与总体方差之间没有显著差异。
两个正态总体的方差齐性检验
比较两个正态总体的方差是否有差异,构造统计量:
F 统计量服从参数为n1-1和n2-1的F 分布。和分别为两个样本的方差,n1和n2的分别为两个样本的大小。
图4-16工作表中A列和B列对两种不同的水稻品种A和B分别统计了8个地区的单位面积产量(单位:kg)。要求检验两个水稻品种单位面积产量的方差之间是否有显著差异。零假设为二者没有差异。

图4-16 两个正态总体方差齐性检验
D2单元格中在Python模式下在公式栏中输入下面的代码:
from scipy import stats as st
dt1=xl("A2:A9").values
dt2=xl("B2:B9").values
fv=np.var(dt1,ddof=1)/np.var(dt2,ddof=1)
fs=st.f(len(dt1)-1,len(dt2)-1)
p=2*min(fs.cdf(fv),1-fs.cdf(fv))
(fv,p)单击Ctrl+Enter键,返回一个元组。元组的第1个元素表示F统计量,第2个元素表示显著性概率。显著性概率p值大于0.05,所以在0.05的显著性水平上接受零假设,认为两个总体方差之间没有显著差异。
数据不满足方差齐性怎么办?
数据不满足方差齐性要求时可对数据进行转换,或者采用非参数的统计方法。
方差已知时单个正态总体均值的假设检验
我们知道,在大样本情况下,不管方差是未知还是已知,都是使用Z检验进行单样本的均值比较。Z检验构造的统计量为:
其中为总体的标准差(方差已知情况下),为样本均值,为总体均值,n为样本大小。在零假设条件下,Z统计量服从标准正态分布。
本小节主要讨论小样本情况下方差已知时单个正态总体均值的假设检验,这种情况下也是使用Z检验。Excel中实现Z检验可以用Excel函数,也可以使用内置Python。
图4-17工作表A列为某工厂随机选取的20只部件的装配时间(单位:分),设装配时间的总体服从正态分布,标准差为0.4,是否可以认为装配时间的均值在0.05的水平上不小于10?此为右边检验,零假设为装配时间的均值在0.05的水平上小于10。

图4-17 用Excel函数进行Z检验
使用Excel函数进行检验。图4-17工作表中,在C2单元格输入公式:
=Z.TEST(A1:A20,10,0.4)
回车后返回检验的显著性概率为0.012674,小于0.05,所以在0.05显著性水平上拒绝零假设,认为装配时间的均值在0.05的水平上不小于10。
使用Excel内置Python进行检验。图4-18所示工作表中,C2单元格中在Python模式下在公式栏中输入下面的代码:
from scipy.stats import norm
data=xl("A1:A20").values
std_error=0.4/np.sqrt(len(data))
z_stat=(np.mean(data)-10)/std_error
p_value=1-norm.cdf(z_stat)
(z_stat,p_value)单击Ctrl+Enter键,返回一个元组对象。元组中第1个元素为Z统计量,第2个元素为显著性概率0.012674。显著性概率小于0.05,所以在0.05显著性水平上拒绝零假设,认为装配时间的均值在0.05的水平上不小于10。
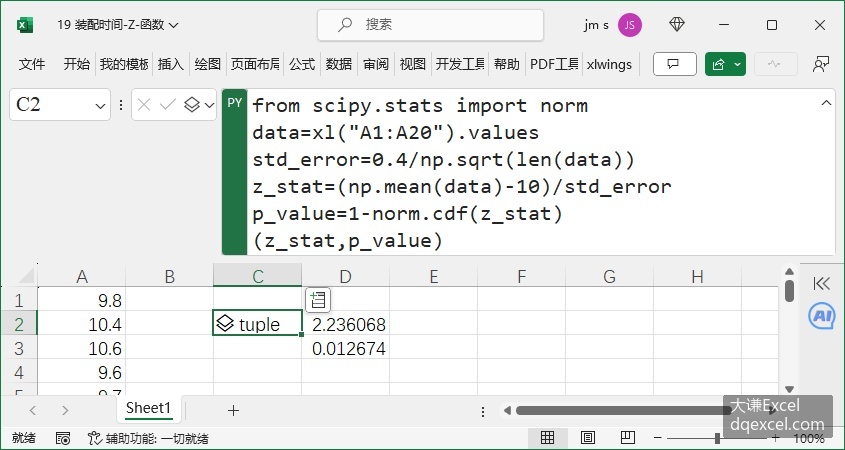
图4-18 用Excel内置Python进行Z检验
方差未知时单个正态总体均值的假设检验
方差未知时单个小样本与正态总体均值的比较使用t检验。统计量T用下面的公式构造:
式中,s为样本的标准差,为样本均值,为总体均值,n为样本大小。
在零假设条件下,该统计量服从自由度为n-1的t分布。
Excel中实现单样本t检验可以用Excel函数,也可以使用内置Python。
图4-19工作表A列为测得的一批钢件20个样品的屈服点(单位:T/CM2),假设屈服点服从正态分布。已知总体均值为5.20,试对该样本的数据进行均值检验。零假设为该样本的均值与总体均值之间没有显著差别。
先用Excel函数实现。如图4-19所示,在C2单元格中输入公式:
=T.DIST.2T((AVERAGE(A1:A20)-5.2)/(SQRT(VAR(A1:A20)/20)),19)
回车,返回显著性概率0.879623,大于0.05,所以在0.05的水平上接受零假设,认为该样本的均值与总体均值之间没有显著差别。

图4-19 用Excel函数进行单个总体的t检验
使用Excel内置Python实现。如图4-20所示,C2单元格中在Python模式下在公式栏中输入下面的代码:
from scipy import stats as st
data=xl("A1:A20").values
r=st.ttest_1samp(data,5.20,alternative='two-sided')单击Ctrl+Enter键,返回一个元组对象。元组中第1个元素为T统计量,第2个元素为显著性概率0.879623,大于0.05,所以在0.05的水平上接受零假设,认为该样本的均值与总体均值之间没有显著差别。
代码中,ttest_1samp函数中的data参数指定分析数据,5.20为总体均值,alternative参数指定进行双侧检验。如果是左边检验,值取”less”;如果是右边检验,值取”greater”。

图4-20 用Excel内置Python进行单个总体的t检验
方差未知时两个正态总体均值差的检验
Python中可使用scipy.stats子包的ttest_ind函数实现方差未知时两个独立样本的t检验。
图4-21工作表中A列和B列对两种不同的水稻品种A和B分别统计了8个地区的单位面积产量(单位:kg)。要求检验两个水稻品种的单位面积产量之间是否有显著差异。零假设为二者没有差异。
Excel中可以用Excel函数进行检验,也可以用内置Python进行检验。

图4-21 用Excel函数进行两个独立总体的t检验
先用Excel函数进行检验。如图4-21工作表中所示,在单元格D2中输入公式:
=T.TEST(A2:A9,B2:B9,2,2)
回车,返回检验的显著性概率0.339295,大于0.05,所以可以在0.05水平上接受零假设,认为两个水稻品种的单位面积产量之间没有显著差异。
接着用内置Python进行检验。如图4-22所示,D2单元格中在Python模式下在公式栏中输入下面的代码:
from scipy import stats as st
data=xl("A2:A9")[0].values
data2=xl("B2:B9")[0].values
r=st.ttest_ind(data,data2)单击Ctrl+Enter键,返回一个元组对象。元组中第1个元素为T统计量,第2个元素为显著性概率0.339295,大于0.05,所以在0.05的水平上接受零假设,认为两个水稻品种的单位面积产量之间没有显著差异。

图4-22 用Excel内置Python进行两个独立总体的t检验
基于成对数据的检验
在实际工作中,为了比较两种方法的差异,常常需要进行对比试验。这样得到的数据具有成对的特点。Python中可使用scipy.stats子包的ttest_ttest_rel函数实现两个成对样本的t检验。
图4-23工作表中A列和B列是在不同蒸汽压下保持了8小时的红花苜蓿半穗中花蜜的含糖浓度数据。要求检验不同蒸汽压对红花苜蓿半穗中花蜜的含糖浓度是否有显著影响。零假设为没有差异。
Excel中可以用Excel函数进行检验,也可以用内置Python进行检验。

图4-23 用Excel函数进行两个配对总体的t检验
先用Excel函数进行检验。如图4-23工作表中所示,在单元格D2中输入公式:
=T.TEST(A2:A11,B2:B11,2,1)
回车,返回检验的显著性概率8.68313E-08,小于0.05,所以可以在0.05水平上拒绝零假设,认为两个水稻品种的单位面积产量之间有显著差异。
接着用内置Python进行检验。如图4-24所示,D2单元格中在Python模式下在公式栏中输入下面的代码:
from scipy import stats as st
data=xl("A2:A11")[0].values
data2=xl("B2:B11")[0].values
r=st.ttest_rel(data,data2)单击Ctrl+Enter键,返回一个元组对象。元组中第1个元素为T统计量,第2个元素为显著性概率8.68313E-08,小于0.05,所以可以在0.05水平上拒绝零假设,认为两个水稻品种的单位面积产量之间有显著差异。

图4-24 用Excel内置Python进行两个配对总体的t检验
4.2.8单个总体均值的非参数检验
前面讲正态分布检验和方差齐性检验的时候讲了,当样本数据不满足统计分析要求时,可以对数据进行转换,或直接使用非参数的方法。本小节介绍单个小样本总体不满足参数检验要求时的非参数检验方法。
单个小样本总体不满足参数检验要求时可以使用Wilcoxon符号秩检验。Python中可使用scipy.stats子包的wilcoxon函数实现单个总体均值的Wilcoxon检验。
图4-25工作表中A列是测得的16只电子元件的寿命x(单位:小时)。假设该种元件的寿命不服从正态分布。问是否有理由认为元件的平均寿命大于225小时?此为右边检验,零假设为元件的平均寿命小于或等于225小时。

图4-25 单个总体的非参数检验
C2单元格中在Python模式下在公式栏中输入下面的代码:
from scipy import stats as st
import statsmodels.stats.weightstats as ws
data=xl("A1:A16").values
r=st.wilcoxon(data-225,alternative='greater')单击Ctrl+Enter键,返回一个元组对象。元组中第1个元素为检验统计量,第2个元素为显著性概率0.510025024,大于0.05,所以可以在0.05水平上接受零假设,认为元件的平均寿命小于或等于225小时。
注意代码中wilcoxon函数的参数设置,因为是单样本,用样本数据减去总体均值225;alternative参数的值为’greater’,表示进行右边检验。
4.2.9两个总体均值差的非参数检验
两个独立总体不满足参数检验要求时可以使用Mann-Whitney U检验。Python中可使用scipy.stats子包的mannwhitneyu函数实现两个独立总体均值的Mann-Whitney U检验。
研究人员试图研究将白鼠置于一种新的驱力和新的环境下时,它们是否能将学会的模仿能力加以推广,研究的方法是首先对5只白鼠进行模仿训练,然后与4只对照鼠进行比较,看每只白鼠需要经过多少次试验才能做到每次试验反应都正确。图4-26工作表中A列和B列是训练鼠和对照鼠为达到学习要求所需要的试验次数。问训练鼠和对照鼠为达到学习要求所需要的试验次数是否相同?零假设为试验次数相同。
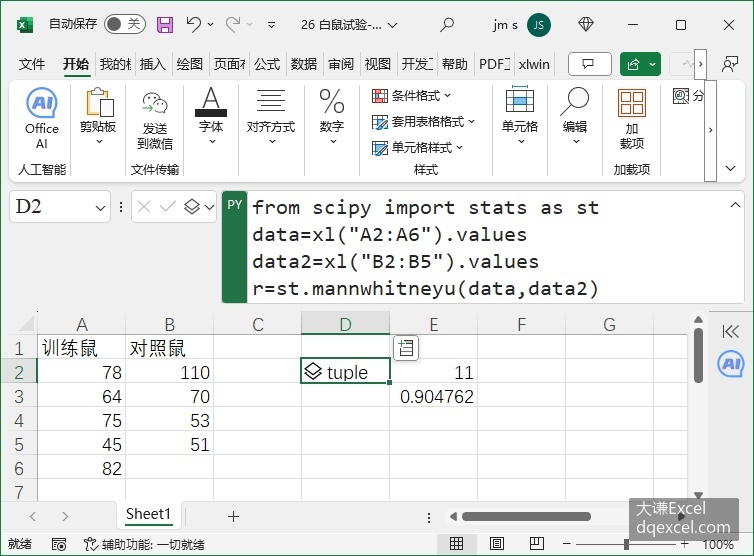
图4-26两个独立总体的非参数检验
D2单元格中在Python模式下在公式栏中输入下面的代码:
from scipy import stats as st
data=xl("A2:A6").values
data2=xl("B2:B5").values
r=st.mannwhitneyu(data,data2)单击Ctrl+Enter键,返回一个元组对象。元组中第1个元素为检验统计量,第2个元素为显著性概率0.904761905,大于0.05,所以可以在0.05水平上接受零假设,认为训练鼠和对照鼠为达到学习要求所需要的试验次数相同。
基于成对数据的非参数检验
两个配对总体不满足参数检验要求时可以使用Wilcoxon检验。Python中可使用scipy.stats子包的wilcoxon函数实现两个成对总体均值的Wilcoxon检验。
经两种处理方法处理以后的小麦,分别种在8对地块上,收成如图4-27工作表中A列和B列所示。问两种处理方法是否有差异?零假设为没有差异。

图4-27两个配对总体的非参数检验
D2单元格中在Python模式下在公式栏中输入下面的代码:
from scipy import stats as st
data=xl("A2:A9").values
data2=xl("B2:B9").values
r=st.wilcoxon(data,data2)单击Ctrl+Enter键,返回一个元组对象。元组中第1个元素为检验统计量,第2个元素为显著性概率0.0390625,小于0.05,所以可以在0.05水平上拒绝零假设,认为两种处理方法有差异。