事件的发生往往与多个因素有关,但各个因素对事件发生的影响可能是不一样的,而且同一因素的不同水平对事件发生的影响也是不同的。通过方差分析,便可以研究不同因素以及因素的不同水平对事件发生的影响程度。[大谦Excel,dqexcel点com]
多个总体的方差齐性检验
方差分析往往要求参与均值比较的多个总体具有相同的方差,所以,对数据进行方差分析之前,有必要先检验数据的方差齐性。检验多个总体方差齐性的方法主要有Bartlett法和Levene法,前者要求多个总体都服从正态分布,后者则没有这个要求,只要多个总体服从同一分布即可。
Python中可使用scipy.stats子包的bartlett函数实现Bartlett检验,用levene函数实现Levene检验。

图4-28 多个总体的方差齐性检验
一位教师想要检查3种不同的教学方法的效果,为此随机地选取了水平相当的15位学生,把他们分成3组,每组5人,每一组用一种方法教学,一段时间以后,这位教师给这75位学生进行统考,统考成绩(单位:分)如图4-28工作表中A-C列所示。要求检验这3组数据所属总体的方差有没有显著差异。零假设为没有显著差异。
E2单元格中在Python模式下在公式栏中输入下面的代码,用Levene法进行检验:
from scipy import stats as st
dt1=xl("A2:A6")[0].values
dt2=xl("B2:B6")[0].values
dt3=xl("C2:C6")[0].values
r=st.levene(dt1,dt2,dt3)单击Ctrl+Enter键,返回一个元组对象。元组中第1个元素为检验统计量,第2个元素为显著性概率0.921728133,大于0.05,所以可以在0.05水平上接受零假设,认为这3组数据所属总体的方差没有显著差异。
H2单元格中在Python模式下在公式栏中输入下面的代码,用Bartlett法进行检验:
r=st.bartlett(dt1,dt2,dt3)单击Ctrl+Enter键,返回一个元组对象。元组中第1个元素为检验统计量,第2个元素为显著性概率0.838481125,大于0.05,所以可以在0.05水平上接受零假设,认为这3组数据所属总体的方差没有显著差异。
单因素方差分析
Python中可使用scipy.stats子包的f_oneway函数实现单因素方差分析。
使用图4-28工作表中A-C列的数据进行分析。要求检验这3种教学方法的效果有没有显著差异。零假设为没有显著差异。
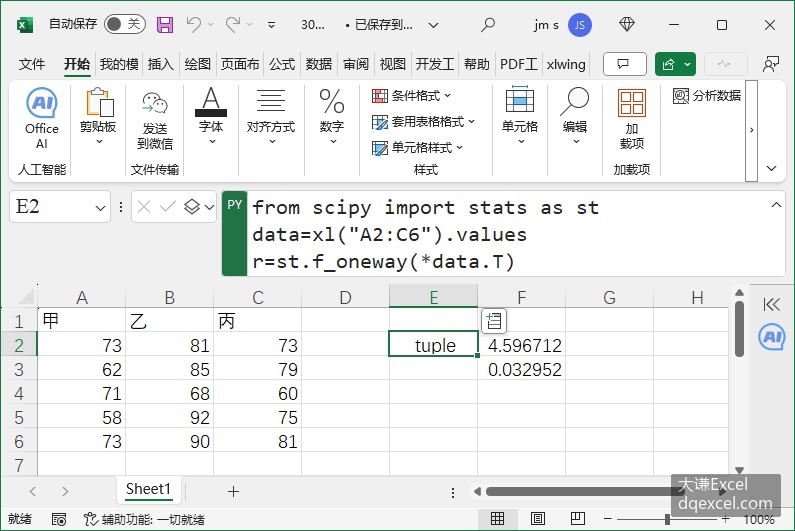
图4-29 单因素方差分析
E2单元格中在Python模式下在公式栏中输入下面的代码:
from scipy import stats as st
data=xl("A2:C6").values
r=st.f_oneway(*data.T)单击Ctrl+Enter键,返回一个元组对象,如图4-29所示。元组中第1个元素为检验统计量,第2个元素为显著性概率0.032951923,小于0.05,所以可以在0.05水平上拒绝零假设,认为这3种教学方法的效果有显著差异。
多重比较
多个总体进行均值比较,假设是3个总体,如果它们的均值有差异,可能有多种情况。比如,可能是第1个总体和第2个总体的均值有差异,或者第2个总体和第3个总体之间有差异,或者其他情况。这些情况都会得到3个总体的均值有差异的结论。所以有必要对各总体两两之间进行均值比较,以进一步确定差异情况,这叫多重比较。
Python中可使用scipy.stats子包的tukey_hsd函数和dunnett函数实现多重比较。
使用图4-28工作表中A-C列的数据进行分析。要求对3种教学方法的效果数据进行多重比较。零假设为多个总体均值两两之间没有显著差异。
E2单元格中在Python模式下在公式栏中输入下面的代码,用tukey_hsd函数进行多重比较:
from scipy import stats as st
dt1=xl("A2:A6")[0].values
dt2=xl("B2:B6")[0].values
dt3=xl("C2:C6")[0].values
r=st.tukey_hsd(dt1,dt2,dt3)单击Ctrl+Enter键,返回分析结果。单击E2单元格中前面的卡片图标,展示分析结果的预览,部分结果如图4-30中所示。可见,第1种和第2种教学方法的效果数据均值比较的结果中显著性概率为0.027,小于0.05,所以可以在0.05水平上拒绝零假设,认为这2种教学方法的效果数据均值有显著差异。其他情况下显著性概率大于0.05,所以在0.05水平上接受零假设,认为其他情况下均值之间没有显著差异。

图4-30 多重比较
E8单元格中在Python模式下在公式栏中输入下面的代码,用三组样本数据绘制箱形图。:
import matplotlib.pyplot as plt
plt.boxplot([dt1,dt2,dt3])单击Ctrl+Enter键,返回一个Image对象。合并单元格区域F8:H14,显示箱形图如图4-30所示。可见,第1种和第2种教学方法的效果数据均值有显著差异。第1种和第3种,第2种和第3种两种情况下,均值则比较接近。
双因素方差分析
Python中可使用statsmodels.stats子包的anova_lm函数实现双因素方差分析。
无重复的情况
为了考察4种不同燃料与3种不同型号的推进器对火箭射程(单位:海里)的影响,做了12次试验,得数据如图4-21工作表A1:D5中所示。要求分析燃料和推进器的不同是否对火箭的射程有显著影响。零假设为没有影响。
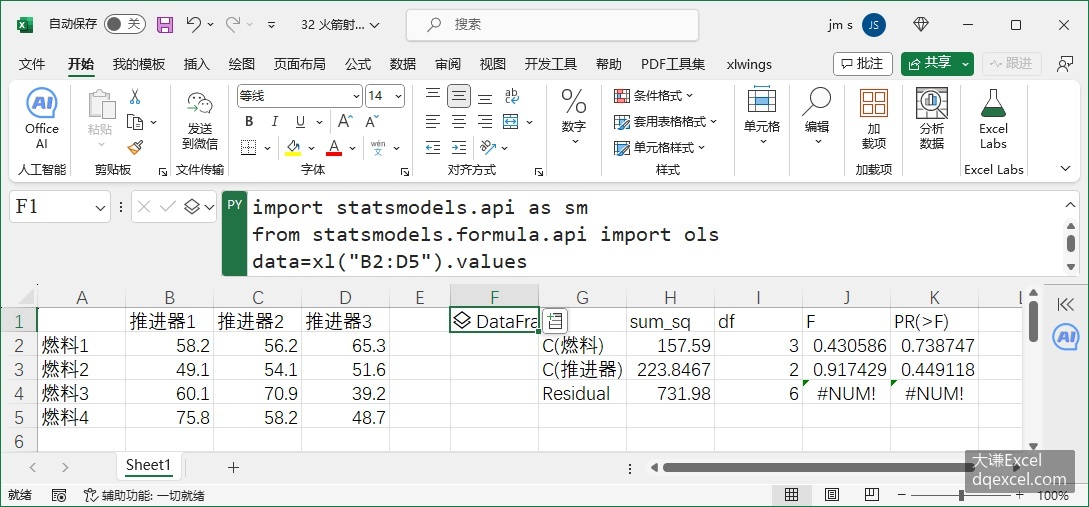
图4-31 无重复双因素方差分析
F1单元格中在Python模式下在公式栏中输入下面的代码:
import statsmodels.api as sm
from statsmodels.formula.api import ols
data=xl("B2:D5").values
df=pd.DataFrame(data)
df.index=pd.Index(['燃料1','燃料2','燃料3','燃料4'],name='燃料')
df.columns=pd.Index(['推进器1','推进器2','推进器3'],name='推进器')
df=df.reset_index().melt(id_vars =['燃料'])
df=df.rename(columns={'value':'射程'})
model=ols('射程~C(燃料)+C(推进器)',data=df).fit()
anova_table=sm.stats.anova_lm(model,typ=2)单击Ctrl+Enter键,返回一个DataFrame对象。展开该对象的内容如图4-21所示,为方差分析表。方差分析表中sum_sq表示各因素和残差项的方差平方和,df表示自由度,F表示F统计量,PR表示与F对应的显著性概率。两个显著性概率都大于0.05,所以在0.05的水平上接受零假设,认为燃料和推进器的不同对火箭的射程没有显著影响。
代码中,df.index属性和df.columns属性为DataFrame指定索引行和索引列,df.melt方法将宽表转为长表。ols函数建立方差分析模型,用fit方法进行拟合,最后用anova_lm函数对模型进行分析,得到方差分析表。
2. 等重复的情况
上面介绍的情况称为无重复的情况,即数据表中每个行索引和列索引相交的地方只有一个测量值。如果有一个以上的测量值,就是重复测量的情况。下面介绍等重复测量的情况。
考察4种不同燃料与3种不同型号的推进器,对于每种搭配各发射火箭2次,得数据如图4-32工作表A1:G5中所示。要求检验各自变量和自变量的交互效应是否对火箭的射程有显著影响。零假设为没有影响。

图4-32 无重复双因素方差分析
A7单元格中在Python模式下在公式栏中输入下面的代码:
import statsmodels.api as sm
from statsmodels.formula.api import ols
data=xl("B2:G5").values
df=pd.DataFrame(data)
df.index=pd.Index(['燃料1','燃料2','燃料3','燃料4'],name='燃料')
df.columns=pd.Index(['推进器1','推进器1','推进器2','推进器2','推进器3','推进器3'],name='推进器')
df=df.reset_index().melt(id_vars =['燃料'])
df=df.rename(columns={'value':'射程'})
model=ols('射程~C(燃料)+C(推进器)+C(燃料):C(推进器)',data=df).fit()
anova_table=sm.stats.anova_lm(model,typ=2)单击Ctrl+Enter键,返回一个DataFrame对象。展开该对象的内容如图4-32工作表单元格区域B7:F11中所示,为方差分析表。方差分析表中sum_sq表示各因素项、因素交叉项和残差项的方差平方和,df表示自由度,F表示F统计量,PR表示与F对应的显著性概率。可见,两个因素项和它们的交叉项的显著性概率都小于0.05,所以在0.05的水平上拒绝零假设,认为燃料、推进器和它们的交互效应对火箭的射程都有显著影响。
代码中,对于等重复的情况,注意ols函数建模时模型的写法。
单因素非参数方差分析
对给定数据进行方差分析时,发现数据不满足方差分析对数据的要求,如正态性、方差齐性等,可以使用非参数的方法来处理。单因素方差分析对应的非参数检验方法是Kruskal-Wallis H检验方法。Python中可使用scipy.stats子包的kruskal函数实现单因素非参数方差分析。
对倾向于教学工作的教师、倾向于恔政管理的教师和恔政管理人员等三组教育工作者的权威主义进行评分,得如图4-33工作表单元格区域A1:C6中所示数据。要求检验这3组教育工作者的权威主义有没有显著差别。零假设为没有显著差别。

图4-33 单因素非参数方差分析
E2单元格中在Python模式下在公式栏中输入下面的代码:
from scipy import stats as st
dt1=xl("A2:A6").values
dt2=xl("B2:B6").values
dt3=xl("C2:C5").values
r=st.kruskal(dt1,dt2,dt3)单击Ctrl+Enter键,返回一个元组对象。元组中第1个元素为检验统计量,第2个元素为显著性概率0.040645907,小于0.05,所以可以在0.05水平上拒绝零假设,认为这3组教育工作者的权威主义有显著差别。
双因素非参数方差分析
双因素方差分析对应的非参数检验方法是Friedman检验方法。Python中可使用scipy.stats子包的friedmanchisquare函数实现双因素非参数方差分析。
为了研究3种不同的强化方式对老鼠的鉴别学习本领有多大影响,在3种强化方式下训练3个匹配的样本,每个样本由18只老鼠组成。进行训练以后,用每只老鼠学会某种“相反”习惯的速度来衡量学习本领。并根据每只老鼠在学习情况转变中犯错误的次数,对每一小组有3只匹配老鼠的18个小组内的每只老鼠的得分评秩,结果如图4-34工作表A-C列数据所示。要求检验不同的强化方式对老鼠的学习情况有没有显著影响。零假设为没有显著影响。

图4-34 双因素非参数方差分析
E2单元格中在Python模式下在公式栏中输入下面的代码:
from scipy import stats as st
data=xl("A2:C19").values
r=st.friedmanchisquare(*data.T)单击Ctrl+Enter键,返回一个元组对象。元组中第1个元素为检验统计量,第2个元素为显著性概率0.012879573,小于0.05,所以可以在0.05水平上拒绝零假设,认为不同的强化方式对老鼠的学习情况有显著影响。