采集到原始数据后,常常用图表或统计量探查数据的特征,并对有问题或不满足统计要求的数据进行预处理。[大谦Excel,dqexcel点com]
描述性统计
在采集到大量的样本数据以后,常常需要用一些统计量来描述数据的集中程度和离散程度,并通过这些指标对数据的总体特征进行归纳。常见描述性统计量如表5-1所示,假设样本数据为。注意,”VBA函数”一列为计算对应统计量的工作表函数,表中只给出函数名称,完整的写法为:app.api.WorksheetFunction.FunctionName,其中FunctionName为函数名,如Min, Max, Average等。
表5-1 常见描述性统计量
| 分类 | 统计量 | 说 明 | 工作表函数 |
|---|---|---|---|
| 集中趋势 | 计算平均值 | Average | |
| 集中趋势 | 中值 | 50%分位数 | Median |
| 集中趋势 | 几何平均值 | GeoMean | |
| 集中趋势 | 调和平均值 | HarMean | |
| 集中趋势 | 截尾均值 | 对样本数据进行排序以后,去掉两端的部分极值,然后对剩下的数据求算术平均值 | TrimMean |
| 集中趋势 | 分位数 | 对于升序排列的数据,处于N%处的数 | Percentile |
| 离中趋势 | 极差 | 最大值减去最小值 | |
| 离中趋势 | 内四分极差 | 75%分位数减去25%分位数 | |
| 离中趋势 | 方差 | ,其中 | Var |
| 离中趋势 | 标准差 | StDev |
图5-1中用一组数据绘制散点图,并在图中标注各种统计量对应的位置。实际应用中,算术平均值容易受异常值的影响,中值和截尾均值则更加稳健。

图5-1 一元数据的描述性统计
下面的代码实现图5-1的绘制。完整代码见:Samples->ch08 统计图表->01 描述性统计->py.py。
#… 省略部分代码
#计算统计量
minv=app.api.WorksheetFunction.Min(y) #最小值
maxv=app.api.WorksheetFunction.Max(y) #最大值
meanv=app.api.WorksheetFunction.Average(y) #均值
median=app.api.WorksheetFunction.Median(y) #中值
rng=maxv-minv #极差
gmean=app.api.WorksheetFunction.GeoMean(y) #几何均值
hmean=app.api.WorksheetFunction.HarMean(y) #调和均值
tmean=app.api.WorksheetFunction.TrimMean(y,0.05) #截尾均值
pt25=app.api.WorksheetFunction.Percentile(y,0.25) #25%分位数
pt75=app.api.WorksheetFunction.Percentile(y,0.75) #75%分位数
iqr=pt75-pt25 #内四分极值
#画横线和标注
draw_line(cht,0,minv,68,minv,'最小值')
draw_line(cht,0,maxv,68,maxv,'最大值')
draw_line(cht,0,meanv,60,meanv,'均值')
draw_line(cht,0,median,68,median,'中值')
draw_line(cht,0,gmean,45,gmean,'几何平均值')
draw_line(cht,0,hmean,45,hmean,'调和平均值')
draw_line(cht,0,tmean,45,tmean,'截尾平均值')
draw_line(cht,0,pt25,55,pt25,'25%分位数')
draw_line(cht,0,pt75,55,pt75,'75%分位数')
#... 省略部分代码频数分析和直方图
对一元数据进行频数分析时,首先将数据从小到大进行排列。根据最小值和最大值得到极差,然后将极差等间隔分割成指定个数的区间,比如10个区间。这样的区间常称为分箱。每个分箱数据的下边界和上边界是可以计算出来的。然后将各原始数据根据大小投放到对应的分箱中,并最终得到每个分箱中的数据。4.1节介绍了利用频数分析结果绘制直方图的方法。
绘制一元数据的直方图可以探查该数据的分布形状,根据直方图的形态可以将分布形状分为陡峭、矮胖、左偏、右偏以及正态等几种情况。
常用统计量峰度和偏度描述和判断数据的分布形状。当峰度>3时,称分布是高尖的,具有过度的峰度,如图5-2中右上角图所示;当峰度<3时,称分布是矮胖的,具有不足的峰度,如图5-2中左上角图所示;当偏度>0时,称分布右偏,或者正偏,如图5-2中左下角图所示;当偏度<0时,称分布左偏,或者负偏,如图5-2中右下角图所示。



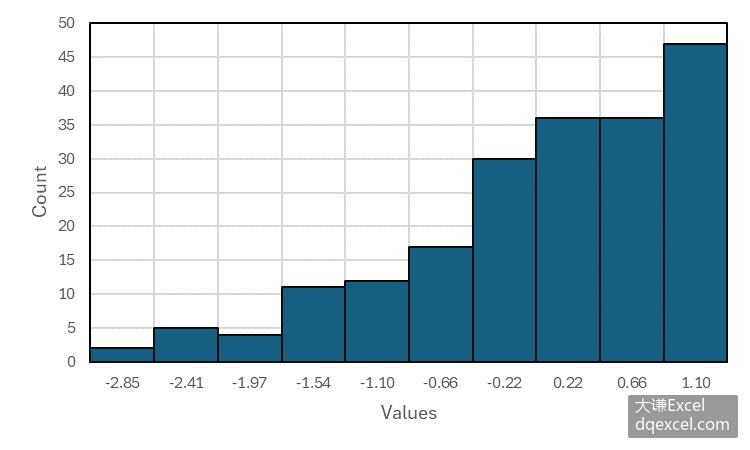
图5-2 不同峰度和偏度的直方图
图5-3用下面的代码生成。完整代码见:Samples->ch08 统计图表->02 数据分布形状->py.py。
root=os.getcwd() #获取当前工作路径
app=xw.App(visible=True,add_book=False) #创建Excel应用
wb=app.books.open(root+r'/data.xlsx',read_only=False) #打开数据文件返回工作簿对象
sht=wb.sheets('Sheet1') #获取指定工作表对象
rng=[0 for _ in range(4)]
rng[0]=sht.range('A2:A201') #各组数据对应的单元格区域对象
rng[1]=sht.range('B2:B201')
rng[2]=sht.range('C2:C201')
rng[3]=sht.range('D2:D201')
for i in range(4):
cht=draw_hist(rng[i],200) #绘制直方图
set_style(cht) #设置样式核密度估计
根据5.1.2小节的介绍,直方图是直接用紧密排列的柱形表现样本数据的分布特征。核密度估计则不同,它是使用非参数的方法,用有限的样本数据对总体进行估计,得到描述总体特征的概率密度函数。
下面的代码用5.1.3小节的数据绘制核密度估计曲线图。完整代码见:Samples->ch08 统计图表->03 核密度估计->py.py。
root=os.getcwd() #获取当前工作路径
app=xw.App(visible=True,add_book=False) #创建Excel应用
wb=app.books.open(root+r'/data.xlsx',read_only=False) #打开数据文件返回工作簿对象
sht=wb.sheets('Sheet1') #获取指定工作表对象
data=[0 for _ in range(4)]
data[0]=sht.range('A2:A201').value #获取数据
data[1]=sht.range('B2:B201').value
data[2]=sht.range('C2:C201').value
data[3]=sht.range('D2:D201').value
app.kill() #退出应用
#从comtypes包中导入CreateObject函数
from comtypes.client import CreateObject
app2=CreateObject("Excel.Application") #创建Excel应用
app2.Visible=True #应用窗口可见
app2.ScreenUpdating=False
wb2=app2.Workbooks.Open(root+r'/data.xlsx') #添加工作簿
sht2=wb2.Sheets('Sheet1') #获取第1个工作表
minx=[0 for _ in range(4)]
maxx=[0 for _ in range(4)]
miny=[0 for _ in range(4)]
maxy=[0 for _ in range(4)]
minx[0]=-30 #4个图表横轴和纵轴的取值范围
maxx[0]=30
minx[1]=0
maxx[1]=1
minx[2]=-3
maxx[2]=4
minx[3]=-6
maxx[3]=4
maxy[0]=0.4
maxy[1]=1.1
maxy[2]=0.5
maxy[3]=0.5
for i in range(4):
shp=sht2.Shapes.AddChart2() #创建空白图表
shp.Left=20+(i+1)*10
cht=shp.Chart #获取图表
cht.ChartType=-4169 #散点图
ax1=cht.Axes(1) #获取横轴
ax2=cht.Axes(2) #获取纵轴
ax1.MinimumScale=minx[i] #设置横轴和纵轴的取值范围
ax1.MaximumScale=maxx[i]
ax2.MinimumScale= 0
ax2.MaximumScale=maxy[i]
cht.HasLegend=False #不显示图例
set_style(cht) #设置样式
ax1.CrossesAt=ax1.MinimumScale #坐标轴相交位置
ax2.CrossesAt=ax2.MinimumScale
#绘制核密度估计曲线图
draw_kde(cht,data[i],0,0,0,255,minx[i],maxx[i])运行代码生成图5-3。核密度估计图的更多绘制方法请参见4.2节。
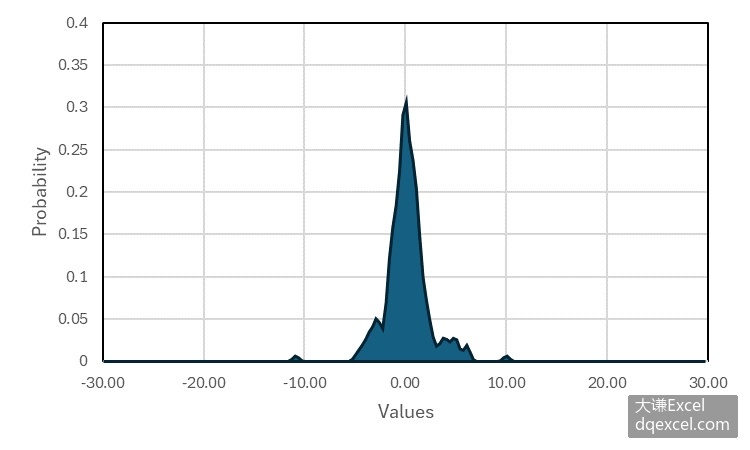



图5-3 不同分布形状数据的核密度估计曲线图